Investigadores Proponen Arquitectura Dual-Branch para Mejora de Voz No Supervisada
Un nuevo estudio presenta una innovadora arquitectura de codificador-decodificador de doble rama que permite la mejora de voz sin la necesidad de datos de entrenamiento etiquetados, superando limitaciones de los métodos supervisados actuales y abriendo nuevas vías para la reducción de ruido en entornos reales.
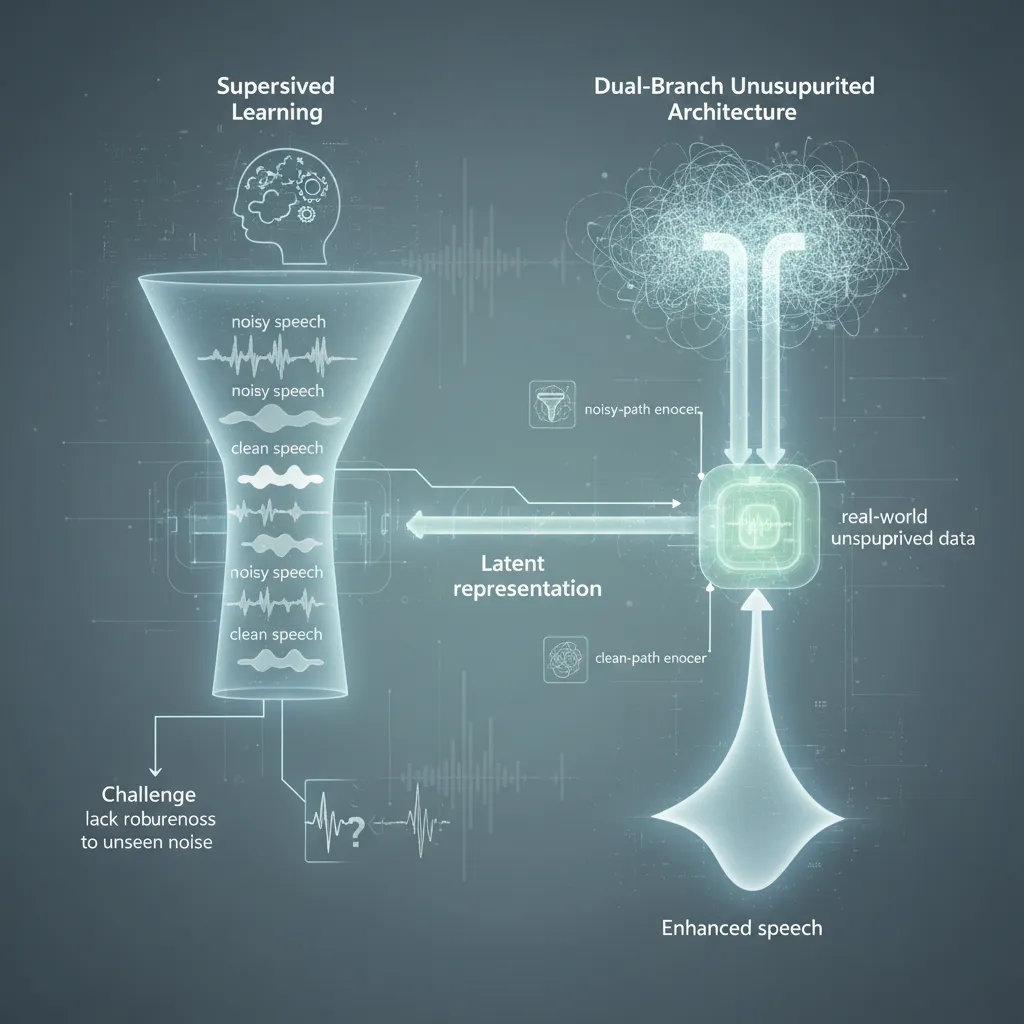
La mejora de voz (SE, por sus siglas en inglés) es una tarea fundamental en el procesamiento de audio, crucial para aplicaciones que van desde asistentes de voz hasta sistemas de comunicación y audífonos. Tradicionalmente, los modelos de SE han dependido en gran medida del aprendizaje supervisado, lo que implica el uso de vastos conjuntos de datos de voz ruidosa y su correspondiente versión limpia. Sin embargo, esta dependencia presenta desafíos significativos, especialmente en entornos del mundo real donde obtener datos perfectamente emparejados es a menudo imposible o extremadamente costoso.
El Desafío de la Mejora de Voz Supervisada
Los enfoques supervisados, aunque efectivos en condiciones controladas, sufren de una falta de robustez cuando se enfrentan a tipos de ruido o entornos acústicos no vistos durante el entrenamiento. Esto se debe a que el modelo aprende a mapear patrones específicos de ruido a voz limpia, y si esos patrones cambian, su rendimiento se degrada drásticamente. La necesidad de coleccionar y etiquetar grandes volúmenes de datos para cada nuevo escenario de ruido limita la escalabilidad y adaptabilidad de estos sistemas.
Una Innovadora Arquitectura Dual-Branch
Un reciente trabajo de investigación propone una solución prometedora a estos desafíos con una arquitectura de codificador-decodificador de doble rama (dual-branch encoder-decoder) para la mejora de voz no supervisada. La clave de esta innovación radica en su capacidad para aprender a separar el ruido de la señal de voz sin la necesidad de pares de datos de voz ruidosa y limpia. Esto se logra mediante un diseño inteligente que permite al modelo inferir las características de la voz y el ruido de forma independiente, incluso cuando solo se le presenta una señal ruidosa.
El modelo se compone de dos ramas paralelas, cada una especializada en extraer diferentes aspectos de la señal de entrada. Una rama podría enfocarse en las características de la voz, mientras que la otra se concentra en el ruido. Al combinar las salidas de estas ramas de manera estratégica dentro de la fase de decodificación, el sistema puede reconstruir una versión mejorada de la señal de voz. Esta separación intrínseca de componentes permite una mayor flexibilidad y adaptabilidad a diversos tipos de ruido, ya que el modelo no está rígidamente entrenado para un tipo específico de interferencia.
Funcionamiento del Modelo No Supervisado
La capacidad de operar sin supervisión es el pilar de esta propuesta. En lugar de depender de etiquetas explícitas, el modelo utiliza principios de aprendizaje autosupervisado o de reconstrucción. Por ejemplo, podría entrenarse para reconstruir la señal de entrada a partir de sus componentes separados, o para maximizar la independencia entre las representaciones de voz y ruido que aprende. Esto permite que el sistema descubra patrones intrínsecos en los datos por sí mismo, haciendo que el proceso de mejora de voz sea mucho más autónomo y generalizable.
Este enfoque no supervisado es particularmente valioso porque reduce drásticamente la barrera de entrada para desarrollar sistemas de mejora de voz. Ya no es necesario invertir grandes recursos en la creación de bases de datos etiquetadas, lo que acelera la investigación y el desarrollo en este campo y permite la implementación en escenarios donde la recopilación de datos limpios es inviable.
Implicaciones y Futuro de la Mejora de Voz
La introducción de esta arquitectura dual-branch no supervisada tiene profundas implicaciones. Primero, democratiza el acceso a la tecnología de mejora de voz, permitiendo su aplicación en una gama más amplia de dispositivos y entornos. Segundo, abre la puerta a sistemas de audio más robustos y adaptables que pueden funcionar eficazmente en condiciones acústicas impredecibles, desde entornos industriales ruidosos hasta conversaciones en espacios públicos concurridos.
El futuro de la mejora de voz podría ver un cambio significativo hacia métodos no supervisados y autosupervisados, lo que llevaría a una mayor resiliencia y autonomía en el procesamiento de audio. Esta investigación es un paso crucial hacia la creación de sistemas de IA que no solo comprendan y generen lenguaje, sino que también interactúen con el mundo auditivo de una manera más natural y eficiente, sin las limitaciones impuestas por los datos etiquetados.





